Projekt Almanaq
Et pseudo-arabisk ord fra det 12. århundrede – så kan det næsten ikke blive mere hemmeligt! Almanak er et andet ord for kalender; men det er mere end det!
Min farfar havde en almanak. Det var en han selv holdt ajour. Han skrev med sirlige små bogstaver alle mulige vigtige oplysninger i sin lommebog. Det var oprindeligt en årskalender trykt med et opslag pr uge i A7, garnbundet og med stift plastik omslag, men han gjorde det til sin almanak.
Hvad er det, der gør projekt Almanaq så hemmeligt?
Hemmeligt er nok også at stramme den! Der er flere elementer af Almanaq som er – skal vi sige usædvanlige - det er måske mere i overensstemmelse med virkeligheden!
Databasen
Starter vi fra neden, fra laget der skal sikre at data ikke forsvinder, så finder vi ganske vist en helt traditionel database, med rækker og kolonner; så vi bruger ikke en af de der moderne dokument orienterede databaser, eller en NoSQL database? Nej! Men den er design'et anderledes end hvad du måske er vant til!
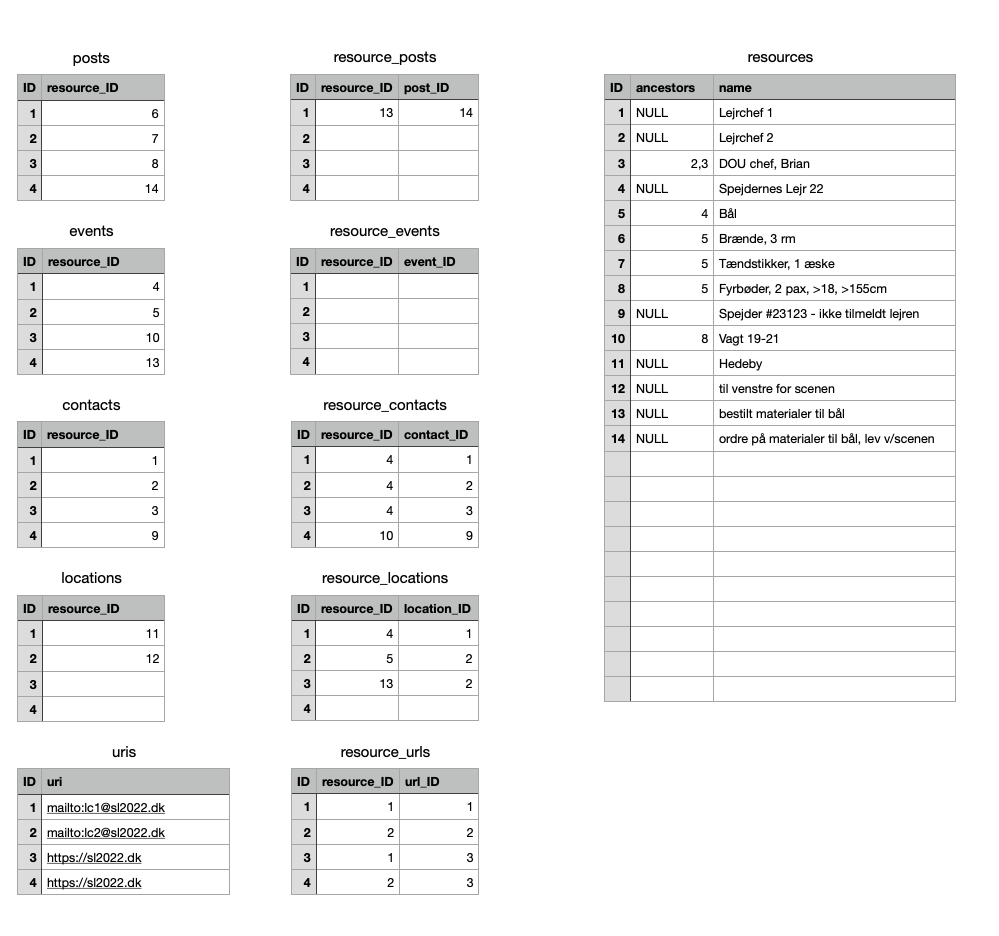
For det første er der kun 20 tabeller! Og reelt set er kun én af dem - nå, ja, teknisk set 7-8 stykker, hvis vi tæller støtte tabeller som fx countries med - beskæftiget med at fastholde bruger data!
Men ville det så ikke netop give mening at bruge en NoSQL database, hvis alt alligevel er samlet i én tabel (sådan som det lyder)? Tjoh, måske, men fordi der er 16 relationer i hjulets center og eger, er vort afsæt at udfordre SQL databasen – men det er da givet at resultatet sikkert viser sig at give et ringere through-put end NoSQL databaserne kan demonstrere; og så spørgsmålet så blot om de vil kunne håndtere de lidt kringlede relationer lige så effektfuldt - vi tror det ikke.
Her kommer så et afsnit – på udenbysk – fordi det er klippet ud af editoren, hvor jeg prøver at holde alt i ét sprog:
I've taken a stab at it - and this is a first draft (but based on quite a lot of experience + readings on the subject)
DB design
This is where we're sketching out the information which Ticket
will persist for us.
Core Elements
Basic systems design
Remember your first lesson in Systems Theory/Designing Information Systems?
I'll bet you got presented to a 'STATE -> PROCESS -> NEW STATE' kind of diagram! Right?
One of the messages that the presenter probably did try to convey was: there will always be someone/something producing/publishing data, some event/process wanting/consuming this data, and eventually someone/something persisting the processed data, and based on this flow of data, you should design a process such that this data is consumed and consolidated.
What are producers/publishers? It's stuff like contacts texting you, warehouses full of products for you to buy, planes full of seats for you to sit in, websites full of posts for you to digest, and everything inbetween.
Processes? That's an easy one! All you gotta do is identify the time frame - the WHEN, and the producer(s) - the WHAT. Perhaps there will be more output then input, perhaps there will be less, but the input is a given; otherwise the process has no state at all and will be very hard to persist in any case, let alone design (with no data, no input, what's let do?)
Designing for change - and considering the basic elements of any action - eventually will guide us towards these keywords: WHAT, WHEN, WHO, WHERE - and the mandatory exception to any rule - HOW
Our first core element
When
Event sounds - at least to me - like a very solid contender for a core element. Identifying the time frame is crucial and Event will allow us this.
Who
Naming the producer/publisher is somewhat more tricky! A common denominator of contacts, warehouses, websites, cars, flats? Partner, Contact, Publisher, Producer, Source?
Our troubles really stress the notion of what basically are the biggest problems developing software:
there are 2 hard problems in computer science: cache invalidation, naming things, and off-by-1 errors
Until genius strikes it's contacts
What
The process implied in identifying the data stream would be one way of naming the 'what'. Basically we could use 'data' but that would indicate state more than action. We will want a verb. Post sounds active and yet points to a "basket of data" or a record in a table. Posts could be a blog post but it could be a stock of some product sitting in an inventory somewhere.
Where
The previous 3 descriptors/attributes have no spatial reference. In that sense the where is a common kid brother of theirs. A proper label would be Location.
A couple of user stories
The resource may be a Contact, a Post, or an Event. The overall user_story will sound somewhat like this:
As a user (contact) I will log in (event) every Monday morning and give my manager (contact) a call (event) during which we will list/prioritize (post on the event/call) what tasks (events) I should focus on for the rest of the week. Observing my manager's calendar (events) and all the customer meetings (events) she's required to take all over the country (locations), I'm rather content being only a junior researcher! Then I'll sit down (event) and spend a few minutes updating (event) my personal research blog. My manager usually will have commented (posts) on one or two of the tasks (events) by the time I'm done updating my blog (post).
Another user story - perhaps more to the point - could be expressed like this (with the elements being abreviated to Event, Contact, Post, Location):
On a jamboree [E] 40000 participants [C] are signed up in 512 groups [C] and 76% of them have started planning their campsites, with requirements for food, wooden rafters, and more [P]. The jamboree campsite planning tools [P] has an enclosed 'webshop' [P] where planners [C] can access all available products [P] and purchase [E] [P] necessary items [P]. Come spring '22 the jamboree finance department [C] will issue [E] preliminary invoices [P] for the groups [C] to settle.
One such planning task [E] is the planner in a particular group [C] realizing a requirement for a kitchen table [E], thus they plan for the construction of a kitchen table [E] and when detailing that construction task [E] they find themselves wanting wooden rafters [P] and sisal rope [P]. They enter the jamboree participation / planning tool (website) and start browsing the webshop [P] for wooden rafters. They come out short on extra long rafters - 10m rafters is not a valid size - and consequently they send a message [P] to the shop-keepers [C] asking for extra long rafters [P]
Resource
We will abstract our 4 core elements in a resource which will allow us to do quite advanced polymorphic associations without experiencing an explosion in the number of required tables - and still keep our global_search capabilities within reach;
Resources may be arranged in a tree-like structure hence for optimizations we need to know the ancestors of any given resource! Name is a proper labeling of a string to identify a post, a contact, an event, a locations. Resources will foreseeably be arranged in lists hence we will require a sort_order both on the resource and on the many_to_many associations tables.
A resource can be whatever the user requires thus we need some way to define the structure of the content - and in a dynamic way 'cause one resource may be a bank, and another an email. We'll use a supporting table for this - and reference it through the content_structure_id.
Data attributes storing privacy related information pertaining to a resource should always be encrypted and segregated - kept in a transaction_log, and anonymizable on request
Content is whatever information this resource 'carries'. One very promising advantage is that our searching strategies suddenly seems quite approachable! SELECT id FROM resources WHERE content like '%something%' eventually will get us ALL records within the entire system mentioning something :o
Another benefit is with regards to GDPR: We will only have to focus our attention to ONE table with regards to encryption, deletion, correction, listing contents, and ultimately obfuscation/anonymization.
Resources (like eg. an email) may have multiple recipients (contacts). An event (resource) may be both a 'birthday', 'familie', etc. That same birthday (event/resource) may have both a seating plan (post), an invitation (post), a shopping list (event (tree)).
Resource may be a landing page (post) - with multiple pages (posts) pointing to it. Each page may have a heading image (post with an 'image' tag).
Resource may be a user (contact) with a set of credentials (credentials) and 3-4 different means of communication (uris)
Resources will be required to be displayed in numerous ways - in lists, records, with only 1-2 data points, etc -
resource fields
- id
- ancestors
- name
- sort_order
- content_structure_id
- content
- created_by references contacts
Resources have quite a few number of many_to_many Ecto associations - here is a list:
- many_to_many events
- many_to_many locations
- many_to_many contacts
- many_to_many tags
- many_to_many posts
- many_to_many urls
- many_to_many sentiments
- many_to_many display_formats
Contacts
Contacts are the first of the three core elements. Contacts may have more credentials provided they store their login information for separate online services with Ticket, but if they are users, they will always have at least one credential.
Contacts may in fact be a wrong labelling - a better name might be: pubsub! A publisher of data (posts)
Contacts are users, friends, employees, customers, suppliers, partners, spouses, children. Contacts persist the WHO
contact fields
- id
- resource_id references resources
- credential_id
- public_shared_key
Contacts belonging to a resource may be recipients, followers, coworkers to whom a task (event) has been delegated, friends joining a party (event), likers of a comment (post), employees (contacts) of a company (contact), participants in a jamboree (event)
resource_contact fields
- resource_id references resources
- contact_id
- role [to|cc|bcc|delegated_to|following|like|..]
- sort_order
Events
Events are the elements birthing Ticket. Events are the ticks providing perspective and a sense of measurement. They persist the WHEN
event fields
- id
- resource_id references resources
- post_id references posts
- start_at
- duration
- due_at
- began_at
- lasted
- ended_at
Events that belong to an element may be a birthday to a contact, publication date to a blog post (post), and so on.
resource_event fields
- resource_id references resources
- event_id references events
- sort_order
Posts
Posts are the last of the three information carrying elements of Ticket and the swiss army knife of them at it. Events will always have at least one post, detailing the what regarding the event. Any kind of information will eventually be "postable" using this element be it an invoice, an attached PDF, a blog post meant for Facebook, a comment on an event, and so on and so forth. Structured data may engage a content_structure. Posts persist the WHAT and HOW
post fields
- id
- resource_id references resources
- type [sms|tweet|snap|fb-update|email|chat|zoom|comment|invoice|..|attachment]
Posts belonging to a resource may be any kind of (un)structured data.
resource_post fields
- resource_id references resources
- post_id references posts
- sort_order
Locations
Locations are written quite differently in various parts of the world - hence an address_format. Further locations may be nothing but a geoposition - in which case the street will double as a label kind of way to address the location when necessary. Locations are the kid brother to the core elements (contacts, events, posts). Content will probably be structured into something like [street|number|floor|building|quarter|city|zip_code|region|state|country|longitude|latitude ]. Locations persist the WHERE
location fields
- id
- resource_id references resources
Locations belonging to a resource (contact,post,event) may be physical addresses, some way point on a hike, or a referenced buena vista in a travel blog (post). Locations may be arranged in a list or referenced within the resource (sort_order) - eg. this clip of Markdown: he looked at [the address](1)
resource_location fields
- resource_id references resources
- location_id references locations
- sort_order
Tags
Tags affords ways to group, categorize, and in other ways segregate data.
tag fields
- id
- label
- sort_order
- popularity
Tags belonging to a resource may be identifiers (work package 1, urgent, estimate), qualifiers (good,bad,excellent), indexes (birthday,meeting,cold calls) and a host of other ways to tag an element. Tags allow for easy display of like elements, eg.: show all events that are a birthday
resource_tag fields
- resource_id references resources
- tag_id references tags
- sort_order
URIs
URI's are exactly what the TLA (three letter acronym) says: a Universal Resource Identifier. Url's are URI's - https://quintupledev.wordpress.com/2016/02/29/difference-between-uri-url-and-urn/, https://www.ietf.org/rfc/rfc2611.txt / (https://www.iana.org/assignments/uri-schemes/uri-schemes.xhtml)
uri fields
- id
- label
- display_format_id
- uri - https://www.w3.org/TR/uri-clarification/
- verified_at
URIs belonging to an element may be a phone number, an email address, a Twitter handle, and a few other important once like a homepage to a contact.
resource_uri fields
- resource_id references resources
- uri_id references uris
- sort_order
Sentiments
Sentiments persists the sentiments offered by any contact on any other resource. One sentiment is a contact offering their +1 on a post, or a number of contacts following an event with interest.
sentiment fields
- id
- icon
- label
resource_sentiment
- resource_id references resources
- uri_id references uris
Display_formats
Display formats affords having a choice of how to display the contents of a contact, a post, an event, and a location. eg.: {{number}} {{street}}<br/>{{city}} {{us_state_abbrev(state)}} {{zip_code}}<br/>{{country}} in the US - https://www.parcelmonkey.com/how-to-guides/how-to-address-mail-to-uk
display_format fields
- id
- label
- format
resource_display_format fields
- resource_id references resources
- display_format_id references display_formats
- purpose eg. [label|list|record|most_important|..]
Credentials
There are a growing number of accepted ways to present yourself to a webservice by means of login credentials stemming from some other service. Amongst the top authentication service providers we find (Nov 2020) Azure Active Directory, Google Authenticator, IBM Cloud App ID, Amazon Cognito, Auth0, and more
credential fields
- id
- platform_id
- content
Supporting elements
The core elements do require a few supporting elements
credential_platforms
credential_platform fields
- id
- name
- content_structure_id
- content
- created_by references contacts
countries
Best way to keep our list of countries fresh is to do curl -X GET --header 'Accept: application/json' 'https://unstats.un.org/SDGAPI/v1/sdg/GeoArea/Tree' within a certain interval.
country fields
- id
- parent_id
- area_code
- name
- --wip--
content_structures
content_structure fields
- id
- encryption, eg: [md5,dsa,rca]
- public_key
- salt
- serialization, eg: [json,csv,binary]
- struct, eg: { ['age','number','number','0'], ['size','string','select','xs,s,m,l,xl,xxl'] }
- --wip--
En lille skrivebordstest (dem skal der mange flere på bordet af, før vi er tilfreds) bekræfter at design'et ihvertfald ikke i udgangspunktet er helt tosset!